Overview
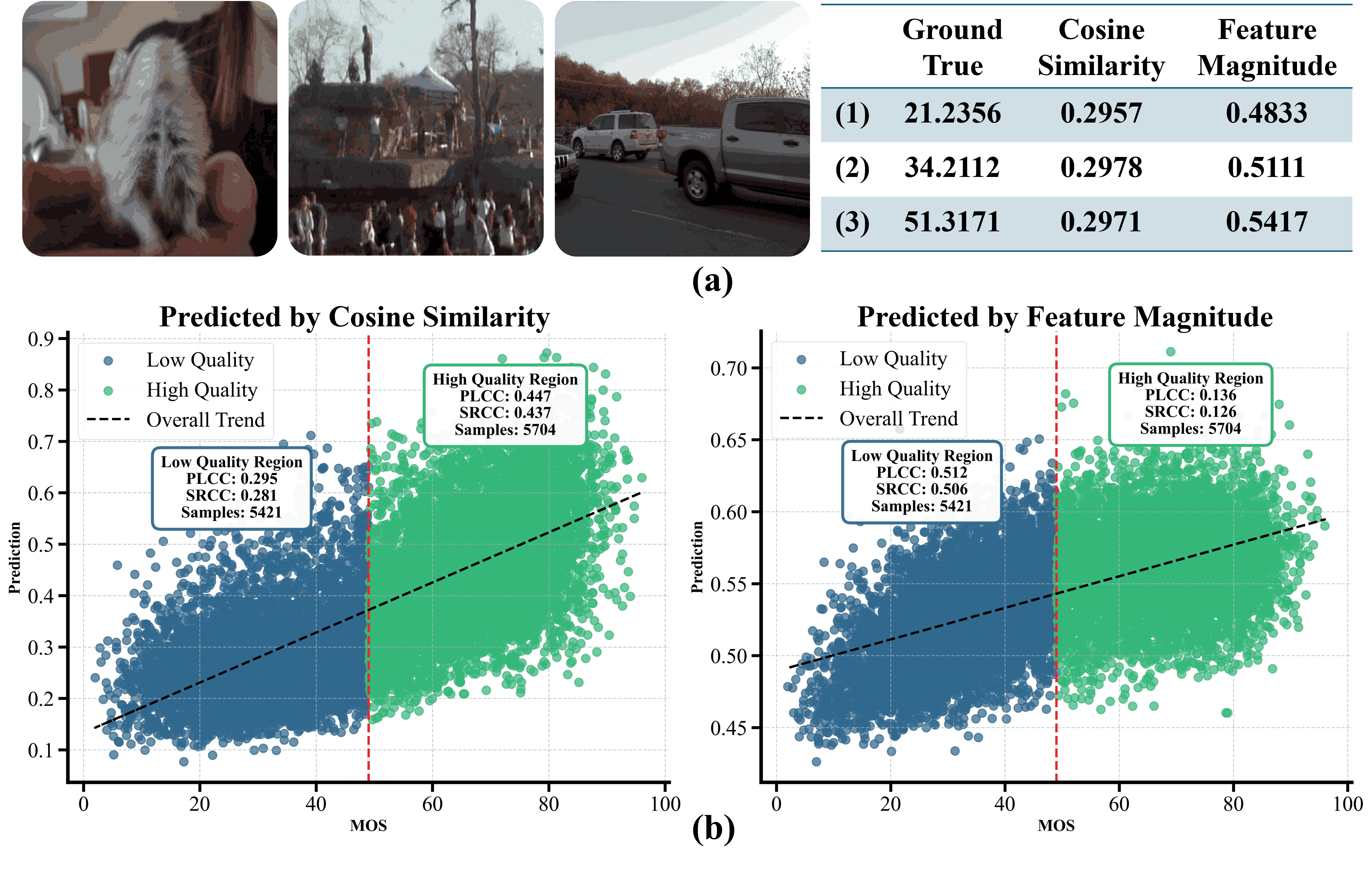
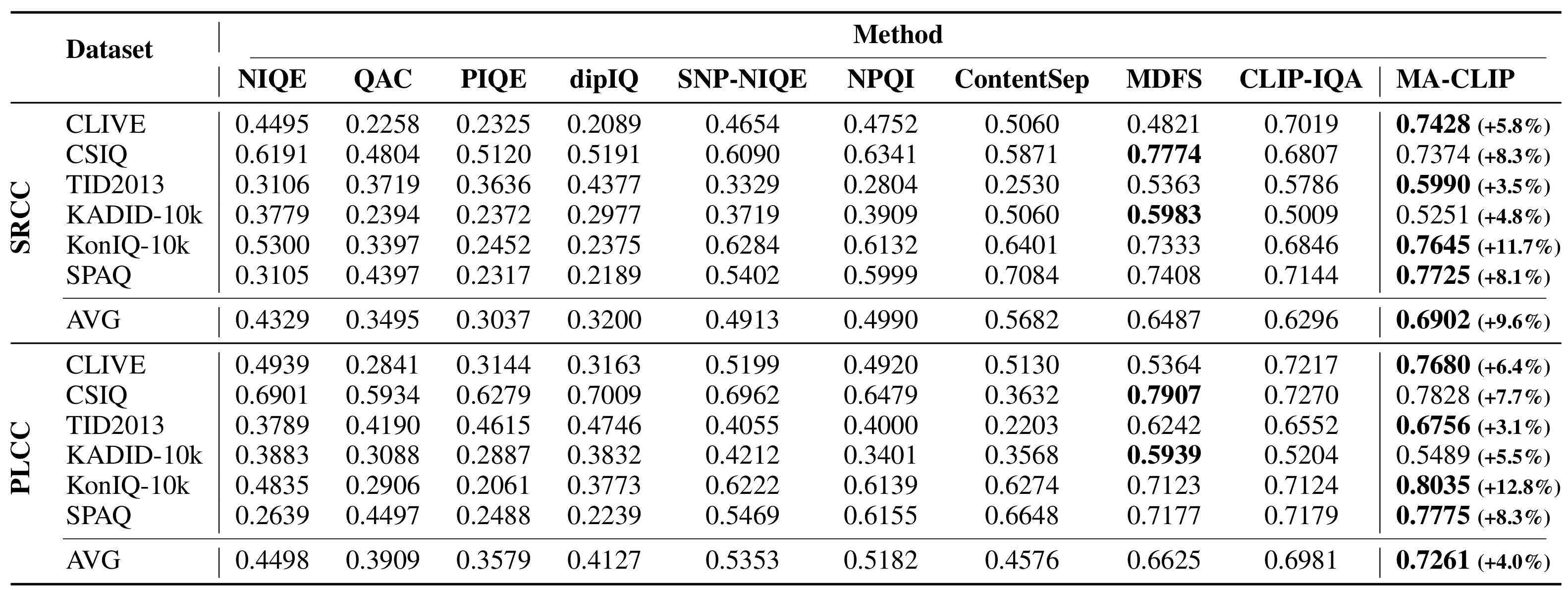
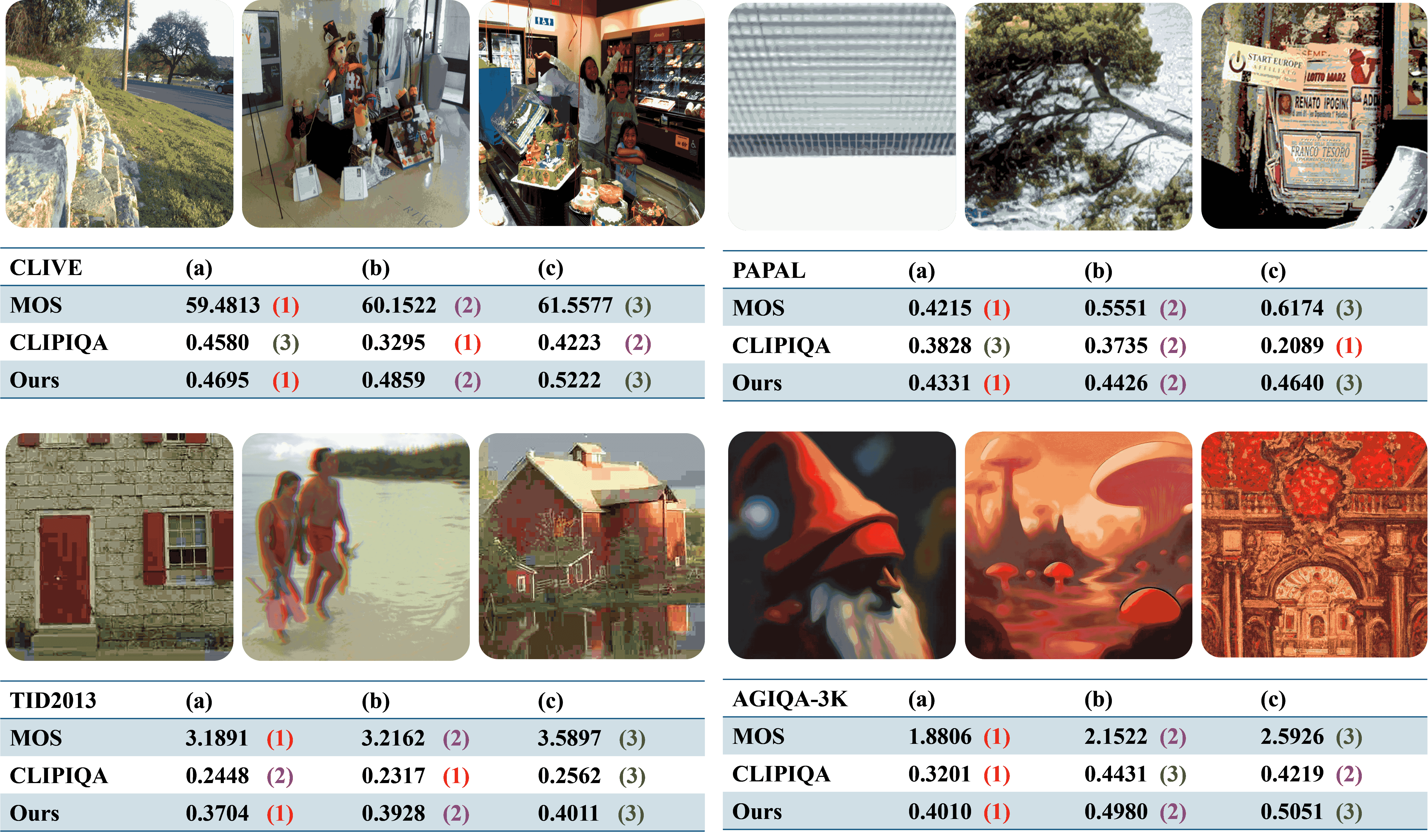
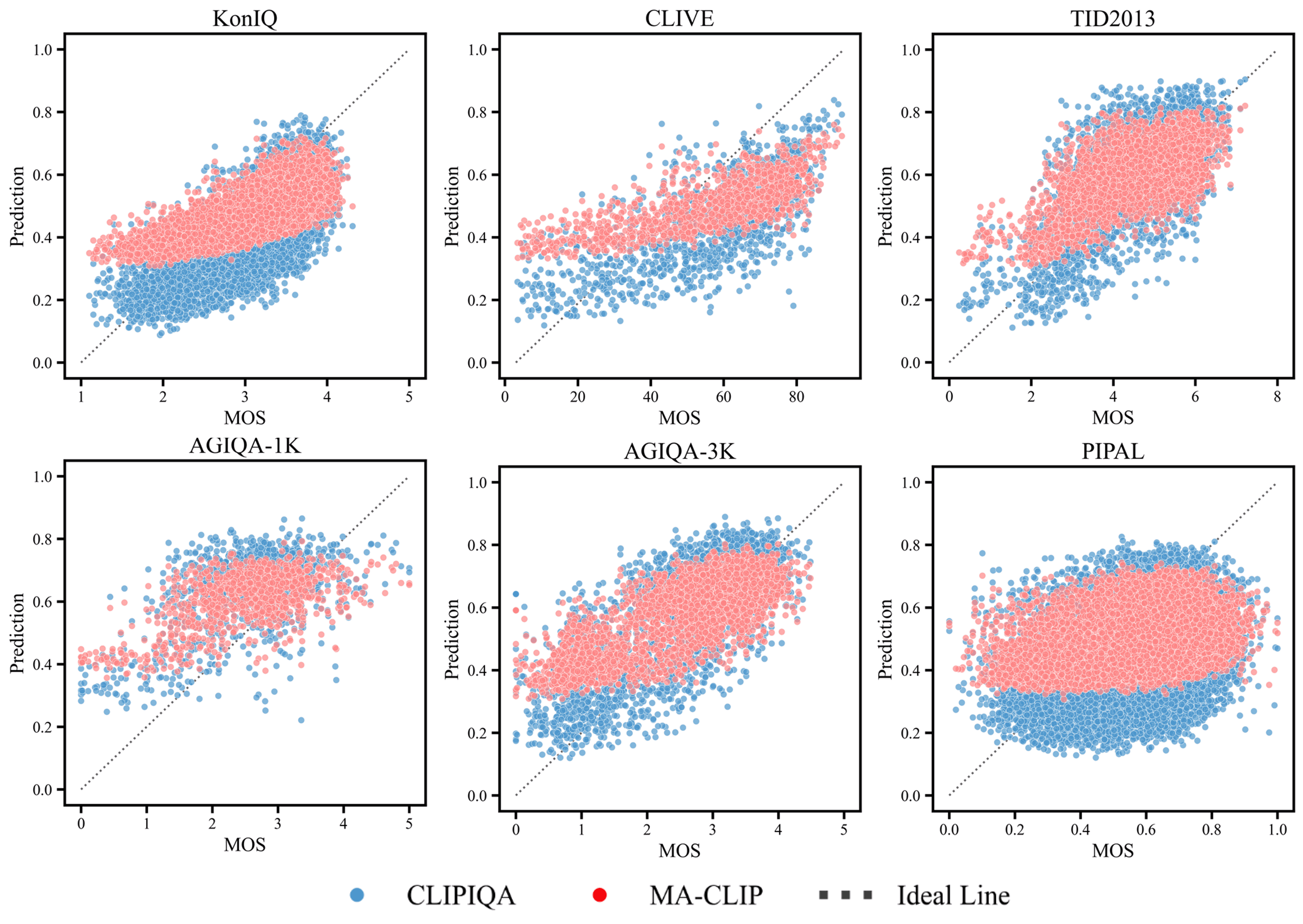
Recent efforts have repurposed the Contrastive Language-Image Pre-training (CLIP) model for No-Reference Image Quality Assessment (NR-IQA) by measuring the cosine similarity between the image embedding and textual prompts such as ``a good photo” or ``a bad photo.” However, this semantic similarity overlooks a critical yet underexplored cue: the magnitude of the CLIP image features, which we empirically find to exhibit a strong correlation with perceptual quality. As illustrated in Fig.1(a), images with widely varying MOS often yield nearly identical prompt-based similarities, failing to capture true perceptual differences. In contrast, the feature magnitude varies consistently with MOS, increasing for higher-quality images and decreasing for lower-quality ones. Moreover, we observe that cosine-based scores are more reliable in distinguishing high-quality images, where semantic features remain well aligned with CLIP’s pretrained distribution, while magnitude cues are more sensitive and consistent in low-quality regimes, where distortions cause semantic misalignment (see Fig.1(b)). T his insight suggests a key conclusion: cosine similarity and feature magnitude are complementary.
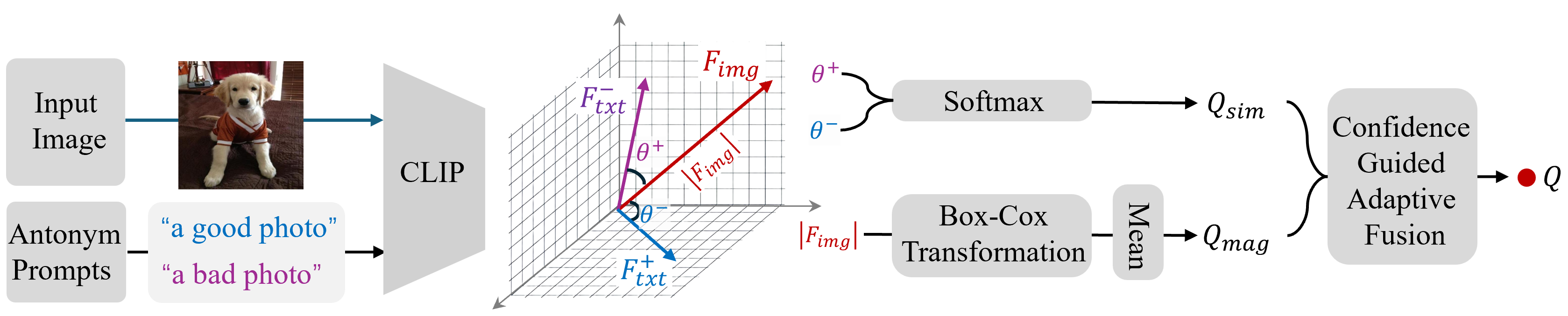
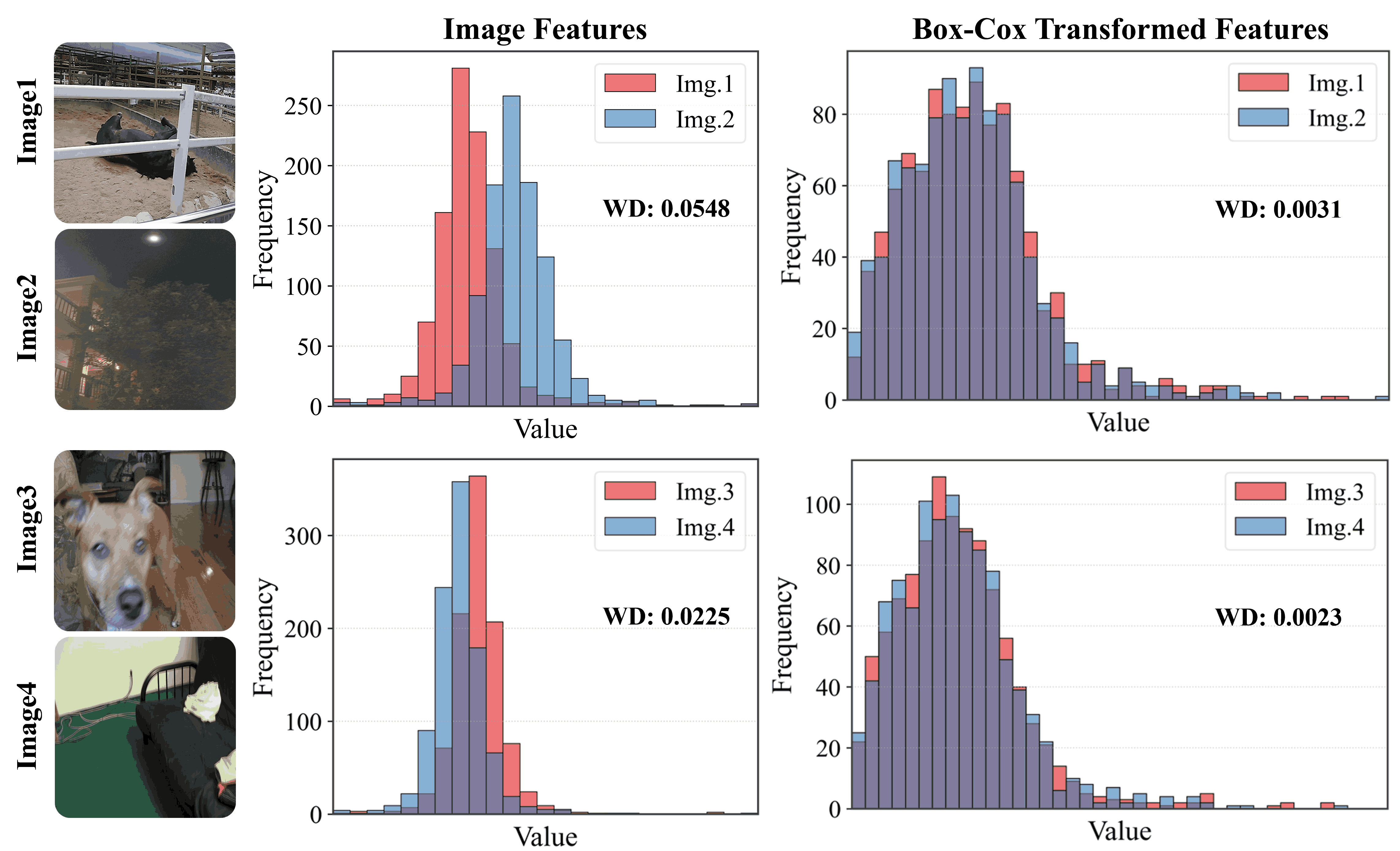
Motivated by this, we propose to leverage both cues jointly rather than relying on either alone. In this work, we introduce a novel adaptive fusion framework that complements cosine similarity with a magnitude-aware quality cue. Specifically, we first extract the absolute CLIP image features and apply a Box-Cox transformation to statistically normalize the feature distribution and mitigate semantic sensitivity. The resulting scalar summary serves as a semantically-normalized auxiliary cue that complements cosine-based prompt matching. To integrate both cues effectively, we further design a confidence-guided fusion scheme that adaptively weighs each term according to its relative strength. Extensive experiments on multiple benchmark IQA datasets demonstrate that our method consistently outperforms standard CLIP-based IQA and state-of-the-art baselines, without any task-specific training.